近日,信息与智能科学学院常姗课题组在智能可穿戴与人机交互(HCI)领域取得重要进展,相关研究成果被 CCF A 类国际会议INFOCOM 2026 录用。这也是该课题组在该领域取得的系列重要进展之一。到目前为止,课题组已经在相关领域发表了多篇 CCF A/B 类会议及期刊论文。
语音是人机交互中最自然、最高效的模态之一,并日益成为移动设备、可穿戴系统和智能助手的主导输入接口。根据最新预测,全球语音识别市场在未来几年依然呈现快速增长趋势。但是语音交互在实际应用中仍面临诸多挑战,特别是在嘈杂环境、隐私敏感场合或针对语音障碍人士时。所以无声语音接口应运而生,其旨在不发声的情况下准确理解内容,这为在无法使用或不方便使用语音的场景下,通过无声语音接口实现自然且鲁棒的人机交互提供一种极具前景的解决方案。
但现有的基于视觉、无线信号或惯性传感器的无声语音接口方案常面临侵入性强、环境敏感或部署复杂等问题。本研究提出一种名为Baro2Talk的新型耳戴式无声语音交互系统,如图1所示,Baro2Talk设计的核心见解是:即使在无声状态下进行的言语发音,也会引起耳道压力的微妙波动。这些压力变化主要由以颞下颌关节(TMJ)为主的(连同下颌、舌头及其他周围口腔结构)发音运动驱动,展现出一致且包含语义信息的模式(如图2所示)。本研究将这些序列称为颞下颌关节主导的压力变化序列(TPVS)。这为建立耳内压力变化与其根本原因(TMJ运动)以及最终语义之间的映射模型提供了契机。
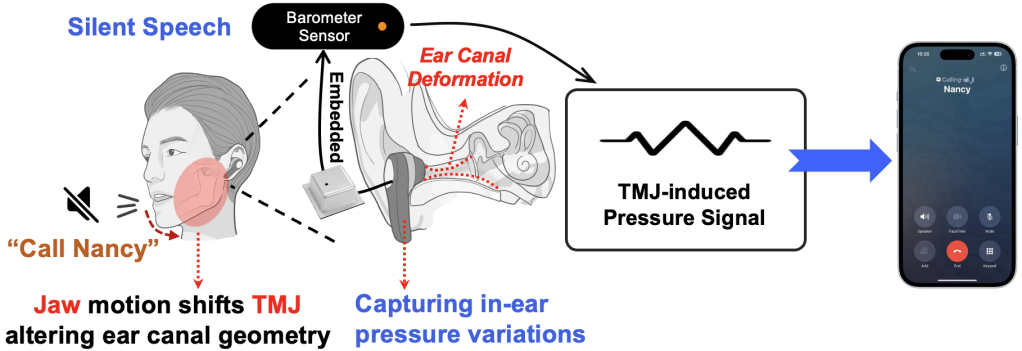
图1 Baro2Talk概念示意图
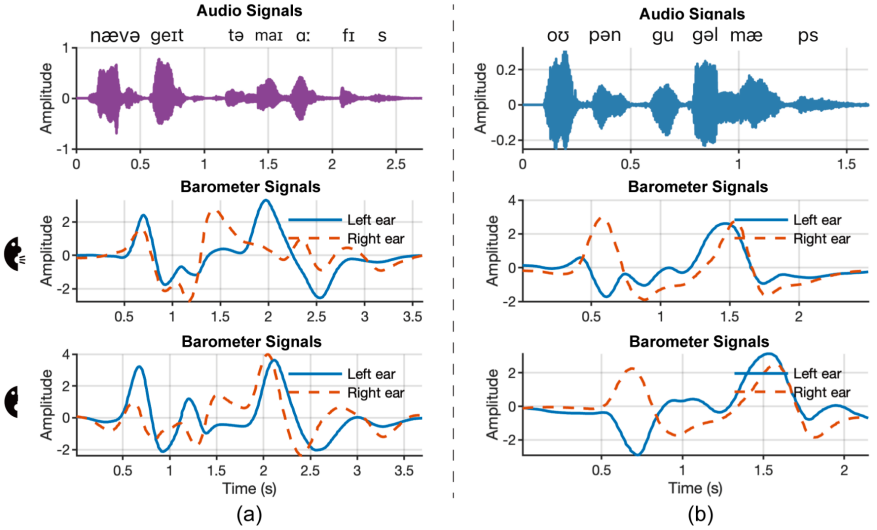
图2 来自两个短语的TPVS示例
为此,本研究将微型气压计嵌入标准耳塞中以捕获TPVS,并利用其重建梅尔语谱图,而非直接还原文本内容。这是因为压力信号的采样率(约100 Hz)远低于音频信号,导致低频TPVS与高维文本嵌入之间存在显著的维度失配。直接将TPVS映射到文本将需要海量的数据。相比之下,梅尔语谱图将TPVS转化为符合语音特征的高频表示,在桥接模态差异的同时保留了共振峰和基频轮廓等关键特征。此外,由于梅尔语谱图是通用自然语音识别系统(如Whisper)的标准输入,所以成为了理想的中间表示。然而,本研究仍然面临三个关键挑战:1.低信噪比与易受干扰的压力信号。本研究提出一套数据预处理流程,包括直流漂移去除、带通滤波和信号放大,以降低噪声并清晰化形变信号。并通过局部稳定性检查增强的短时能量检测方法,从连续的TPVS中提取无声语音形变事件;2.用户间差异与节奏多样性。如图3所示,本研究使用领域对抗学习训练了一个Baro-Encoder,以提取用户不变的语义特征。同时,设计了一种基于节奏感知的数据增强策略,生成TPVS的时域扭曲变体,增强对说话速度变化的鲁棒性;3.非声学模态与缺乏细粒度监督。如图4所示,与基于声带或扬声器振动的语音信号不同,TPVS源于人类内部发音动作,不含声能。其频谱图在语音领域并非固有有意义,使得直接映射到音频频谱图变得不可行。此外,无声语音缺乏对齐的音素或帧级标签,阻碍了传统监督回归或基于对齐模型的使用。
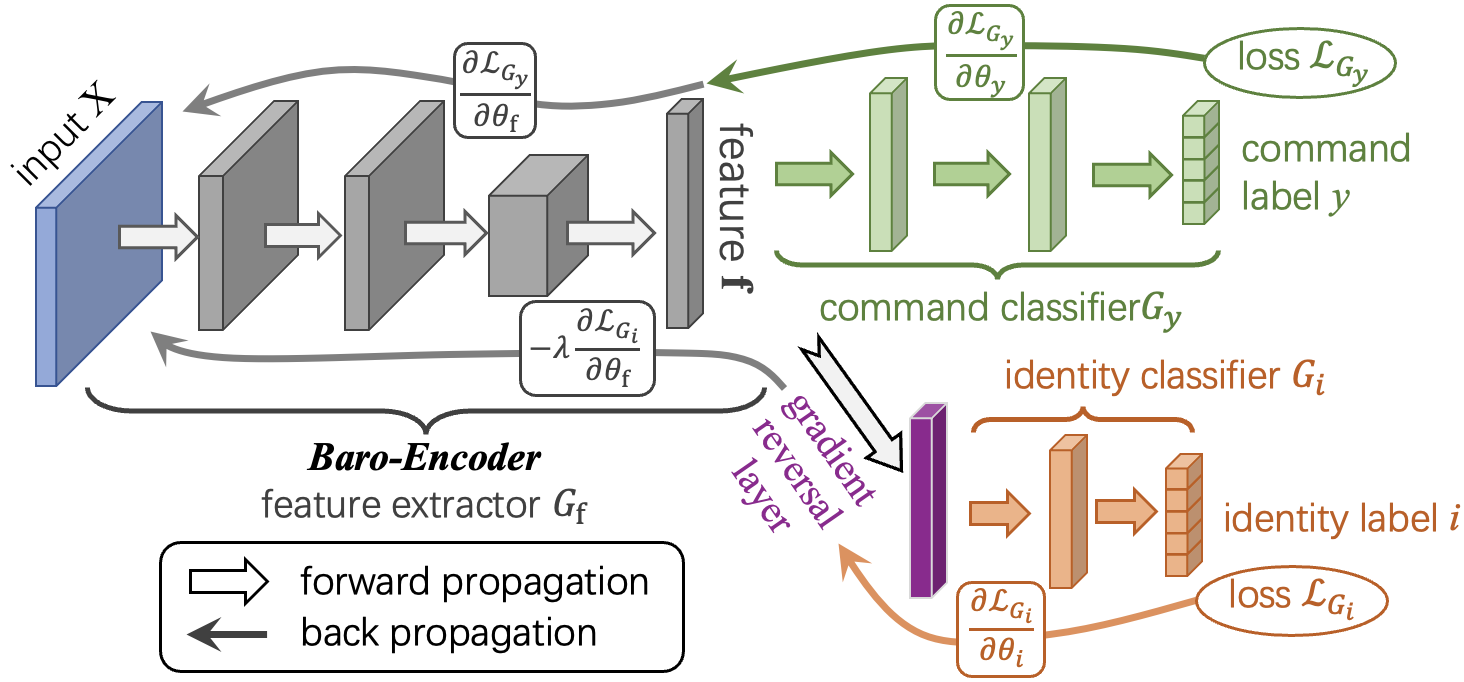
图3 对抗预训练Baro-Encoder示意图
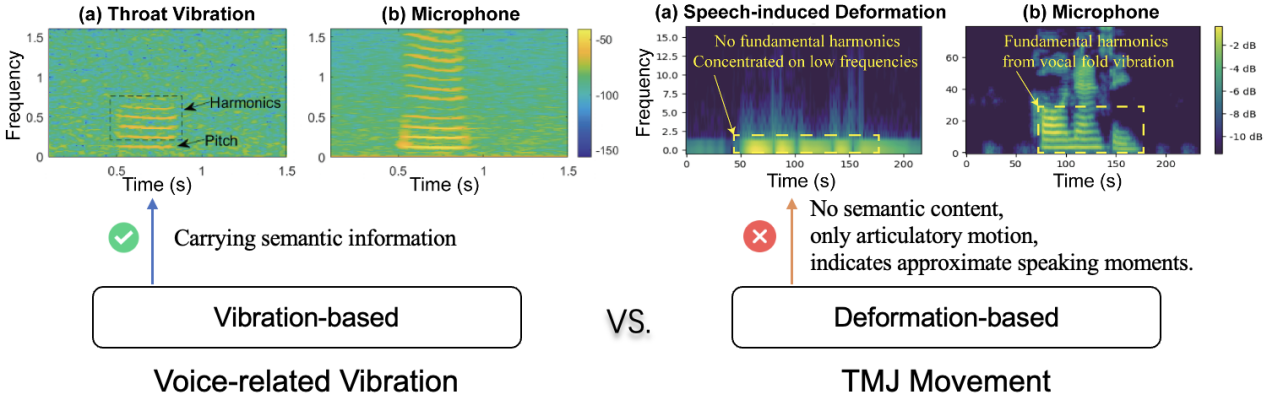
图4 不同生理机械运动下的梅尔语谱图差异对比
为此,如图5所示,本研究提出一个三阶段梅尔谱图重建管道,将语义理解与梅尔谱图生成解耦。首先,名为S-Former的语义编码器将句子的完整TPVS映射到与其文本嵌入共享的潜在语义空间,避免了对齐需求。其次,利用学习到的潜向量通过生成式网络MS-GAN逐步生成粗粒度梅尔语谱图。最后,通过自适应残差学习实现的音素增强(PEARL)对其进行精细化,从而在无声学监督的情况下实现梅尔语谱图的高保真重建。
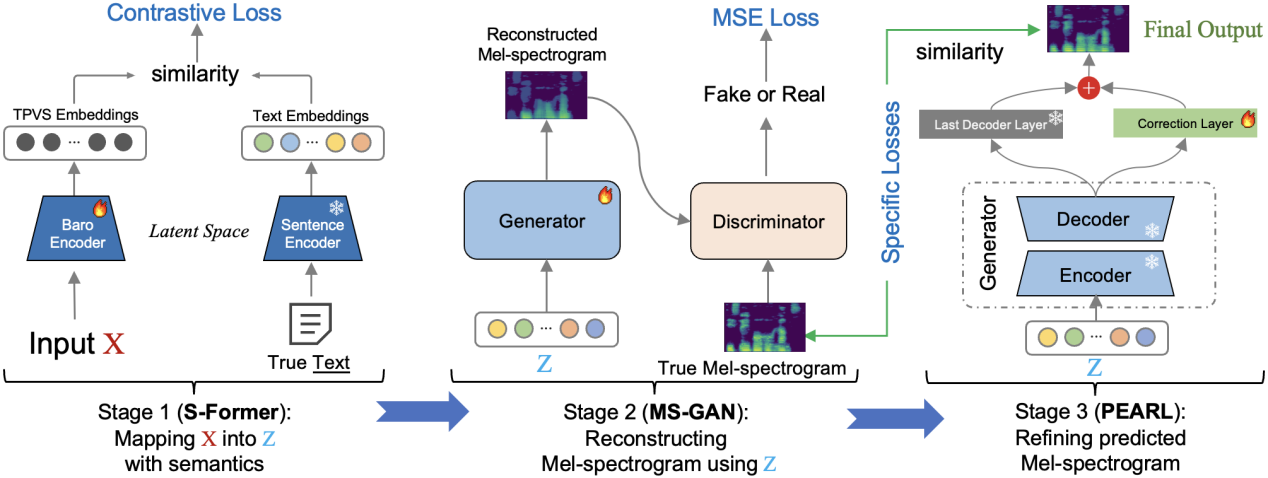
图5 三阶段梅尔谱图重建管道
在无声语音交互过程中,梅尔语谱图的重建质量直接决定了最终ASR文本预测的准确性。由于TPVS不包含声学谐波,重建过程极具挑战。如图6所示,本研究通过消融实验,清晰地展示了系统各模块对梅尔语谱图重建效果的贡献。
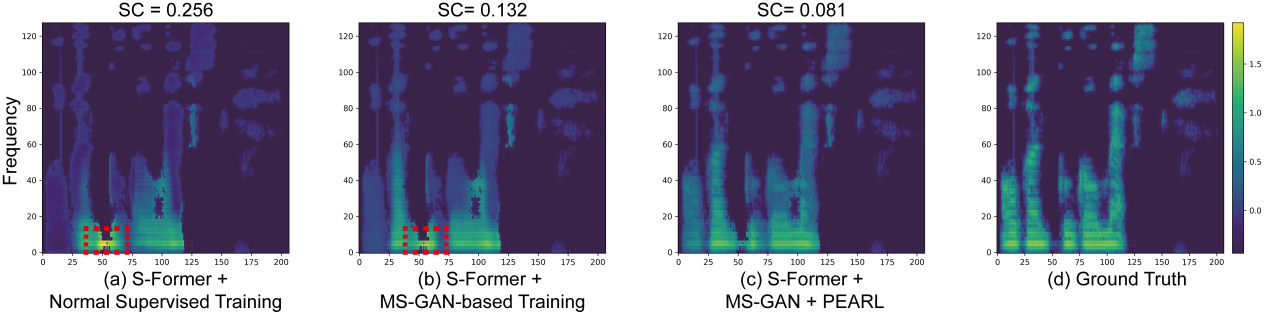
图6 梅尔语谱图重建效果对比
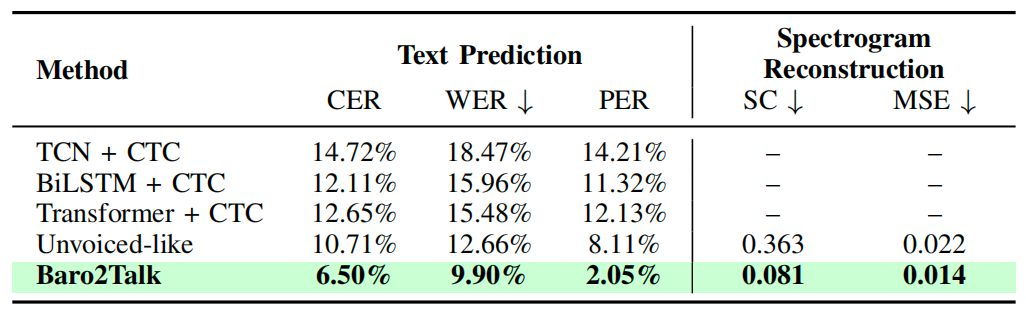
本研究跨越六个月,收集来自25名参与者(包含无声和有声发音条件)的数据集对该系统进行了评估。如表1所示,该系统在文本预测和梅尔语谱图重建方面均由于代表性的SSI基准方案。
表1 不同方法的文本预测精度和梅尔语谱图重建效果
本研究工作发表在计算机学会推荐A类会议IEEE International Conference on Computer Communications(INFOCOM 2026)上。